An Explanation
Introduction
So... What is this anyway?
If you've started to read this little "story", you may have noticed that it's written in a kind of cod-Dickensian style but it doesn't make much sense to start with and it makes even less if you persevere.
That's because it's not actually "written", per se... Instead, this was generated by a simple computer program that had some classic Victorian Christmas literature to draw on which it then tried to emulate using a mathematical technique known as a "Markov Chain". See the end for the short list of source works.
Describing Traffic Lights
Say you took a clipboard and a folding chair down to a local road intersection with a simple traffic light. And you set down in your folding chair and every time the light changed, you recorded it on the clipboard. You'd probably wind up with something like this:
red green yellow red green yellow red green yellow...
Very... regular. And not very interesting. You can describe it a little more compactly by saying something like:
red -> green -> yellow -> red
That is to say, the light started at red when you began observing it, then cycled through green and yellow, then back to red. If you sat there all day (uncomfortable in a folding chair, so congratulations on your persistence!) and recorded every change, you will have noticed that red always changes to green. No exceptions for this simple light. Green always changes to yellow and yellow always changes to red. So the probabiility of the next colour is unity (1.0). (The accident where the truck ran into the traffic light controller box and all the lights turned on was after you'd picked up your folding chair and gone home, so it's not in your data.)
Here's a diagram that shows all the possible states of the traffic light, with the probability of changing to the new state:
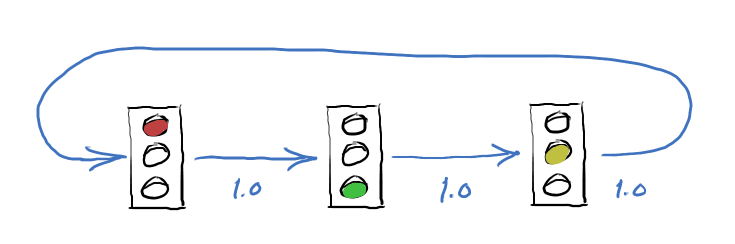
Now, what if the traffic light is a little more complex? Perhaps it has a fancy lane sensor to determine that cars are waiting in the left turn lane. If so, then instead of going directly to green, it will first show a left turn arrow (a "protected left") to empty that lane, then change to full green. Now your data starts to get more interesting:
red green yellow red arrow green yellow red green yellow red...
After analyzing your observations, you determine that the arrow turned on half the time the light shifted from red. So, fifty percent of the time. That means the probability of an arrow showing (instead of full green) is 0.5. Let's redraw the state diagram:
Wait! If the probability going into the arrow state is 0.5, why is it 1.0 going out? Because the arrow always changes to full green. It never does anything else (in the data).
Describing Text
We can use the same technique to describe the text in a body of writing. It's more complicated than a traffic light, but not too bad. Instead of considering what colour changes to what, we look instead at what words follow another. Conveniently, text is already written out, so we don't have to sit on a folding chair for hours.
Let's first look at a simple example:
A MAN A PLAN A CANAL PANAMA
This isn't too far off from the traffic light states above. However, it is a little more involved. One thing we can do to help sort it out is to make a list of the words as we encounter them and record what word follows each one.
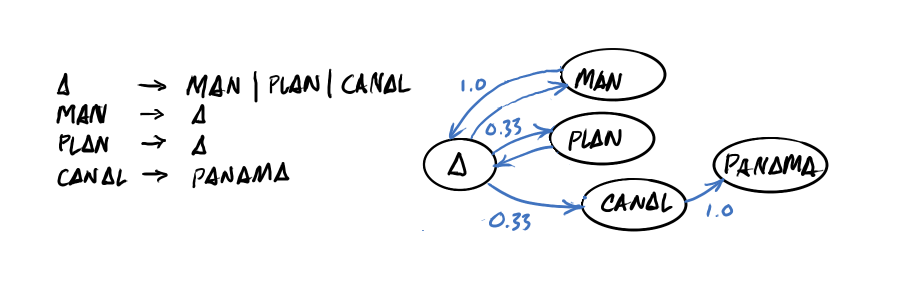
"MAN" and "PLAN" are only followed by "A", and similarly, "CANAL" only leads to "PANAMA". Just as with the traffic light example, words that lead only to a single other word have probability 1.0 — certainty.
However, the word "A" is possibly followed by one of three different words — "MAN", "PLAN" and "CANAL". Since there are three possibilities, the probability is ⅓ that any particular one might be chosen. You can see this in the state diagram with the paths marked as 0.33 probability.
For the Markov Christmas Carol, I used three different chunks of Christmas related text (see Sources). The analyze function sifts through all the text to work out what follows each word. Then the odds function converts it to a list ordered by probability.
> (define WORDS (string-split (file->string "./dickens-christmas-stripped.txt"))
> (define CHAIN (odds (analyze WORDS)))
> (hash-ref CHAIN "Ghost")
'((1/41 "bothered")
(1/41 "stopped")
(1/41 "held")
...
(2/41 "pointed")
...
(12/41 "of"))
In this case, for the word "Ghost", there are 41 followon words. Of these, some are repeats, so they're more likely. The words "bothered" and "stopped" have one out of 41 chances, while "pointed" is used twice and "of" twelve times in the source text (makes sense considering how often "Ghost of Christmas..." shows up, right?).
Generating New Text
Now that we've got a compact description of how the words are all used in the source texts, we can generate a new document that statistically matches the source texts. That is to say, it will have similar word choice (since the only words the computer knows about are the ones in the sources) and (if we're lucky) some of the same stylings.
This is done by picking a likely looking starting word and then randomly choosing among its followon words based on their probability. The sentence function takes a starting word and constructs a (not necessarily grammatical sentence) from it. Here are five different possible sentences that might be created using the start word "Ghost":
> (for ([i 5]) (println (string-join (sentence CHAIN '("Ghost")))))
"Ghost again upon the word, it was plain that I could never
been man who had the City—I don’t know not quite familiar
weapons, then stopped."
"Ghost of fiery red, his knee; for ever like), which cast
about, and made such a mighty Mansion House, gave me by which
subsisted until they saw no good friend,” said Bob, "for he
sits, and soon he clapped him and far from this festive season
brings, may be told you."
"Ghost and marked the two families are dead silence of thing
any terms, but he was, that Old Cheeseman’s cowardice."
"Ghost replied."
"Ghost of its home—where was at any worth millions—could buy
my penance," pursued John, “I have no change."
Obviously, millions more are possible. In the generator program, we become more and more abstract with a para function and finally story to generate an entire epic in less time than it took Chuck D. to set quill pen to paper.
Does the computer "understand" what it was writing? Not a bit of it. The only things it knows are what words are likely to start a sentence, the probability that one word will follow another in the source text and (when it's writing out) that a period ends a sentence. The words themselves have no intrinsic meaning to it. They could be in a different language, or even completely random groupings.